
Executive summary
Disclosed is the capability to leverage the canon texts in different languages to derive and evaluate the effectiveness of language translation models for application on non-canon text. This is specifically useful when generating initial language translation models for languages, which are as yet unclassified, such as native/indigenous languages.
Background and Problem statement
The word canon comes from the Greek κανών, meaning rule or measuring stick. In fiction, canon is the material accepted as officially part of the story in an individual universe of that story. In works of fiction, canon provides thus a structure for internal consistency within the fictional universe itself.
The Bible has been translated into many languages from the biblical languages of Hebrew, Aramaic and Greek. As of September 2016 the full Bible has been translated into 636 languages, the New Testament alone into 1442 languages and Bible portions or stories into 1145 other languages. Thus at least some portion of the Bible has been translated into 3,223 languages. Translations of the Qur’an are interpretations of the scripture of Islam in languages other than Arabic. Qur’an was originally written in the Arabic language and has been translated into most major African, Asian and European languages.
“Translation studies” is an academic interdiscipline dealing with the systematic study of the theory, description and application of translation, interpreting, and localization. As an interdiscipline, Translation Studies borrows much from the various fields of study that support translation. These include comparative literature, computer science, history, linguistics, philology, philosophy, semiotics, and terminology.
There are many mechanisms for performing machine translation of languages, from rule-based approaches, to the resurgence of statistical approach, which leverage word-based translation, phrase- based translation, syntax-based translation, hierarchical phrase-based translation, and etc. mechanisms. The statistical approach to machine translation is often seen as superior to the rule-based approach due to the latter’s requirement to formally develop the linguistic rules which are costly and do not apply well to the general case. Whereas the statistical approach leverages existing generally produces more fluent translations owing to the use of a language model. It stands to reason then that the efficacy of a translation job is directly related to the choice to the model used. The problem is then how to choose the model.
Historically, religious canon texts are amongst the first to be considered for translation into a new language. The formal nature of canonicity providing thus a roadmap for language scholars to agree on accurate translation of the written word, these static translations encode relationships, thus, between any two languages. This work is to extract and formalize these relationships such that evaluation of statistical language translation models can be performed in the abstract to ascertain the most effective, efficient and accurate model to be applied between any two given languages.
Novelty
A system and method for unambiguous evaluation and classification of the effectiveness or accuracy of any arbitrary language translation model between two languages.
Advantages and value
- The advantage of this method is that by leveraging the peer-reviewed work done by translation studies scholars in performing translations of canon text we have ready-made ground truth of both the input and output state.
- The value of this method is in being able to evaluate the effectiveness of a given statistical machine translation language model against another in the absolute. To be clear, our teaching provides the ability to train and refine the translation engine for a given language pair.
Method
Given a language pair (source/target) and a plurality of candidate language translation models
- Apply one initial translation model to translate canon text in source language to generate candidate canon text target in the target language.
- Perform word-based comparison of resultant candidate text against the canon text in the target language to generate a compatibility or faithfulness score. This score indicates the efficacy of the selected language model in translating from source to target as a scalar.
- The result is captured as a tuple of { source , target , model , score } values.
- Select another model from the plurality of candidate models. Repeat steps 1, 2, and 3 until all models exhausted
- Select the model with the highest score for given source/target language pair as the model to be employed.
In some embodiments, the use of an intermediary language is leveraged to translate between a source and target text. In such cases the
- Apply one initial translation model to translate canon text in source language to generate candidate canon text in the intermediary language.
- Apply one initial translation model to translate the candidate canon text in the intermediary language to generate candidate canon text in the target language.
- Perform word-based comparison of resultant candidate text against the canon text in the target language to generate a compatibility or faithfulness score. This score indicates the efficacy of the selected language model in translating from source to target as a scalar.
- The result is captured as a tuple of { source , target , intermediary , model1, model2, score } values.
- Select another model from the plurality of candidate models. Repeat steps 1, 2, and 3 until all models in all intermediary languages are exhausted.
- Select the model with the highest score for given source/target language pair as the models and intermediary to be employed.
Detail
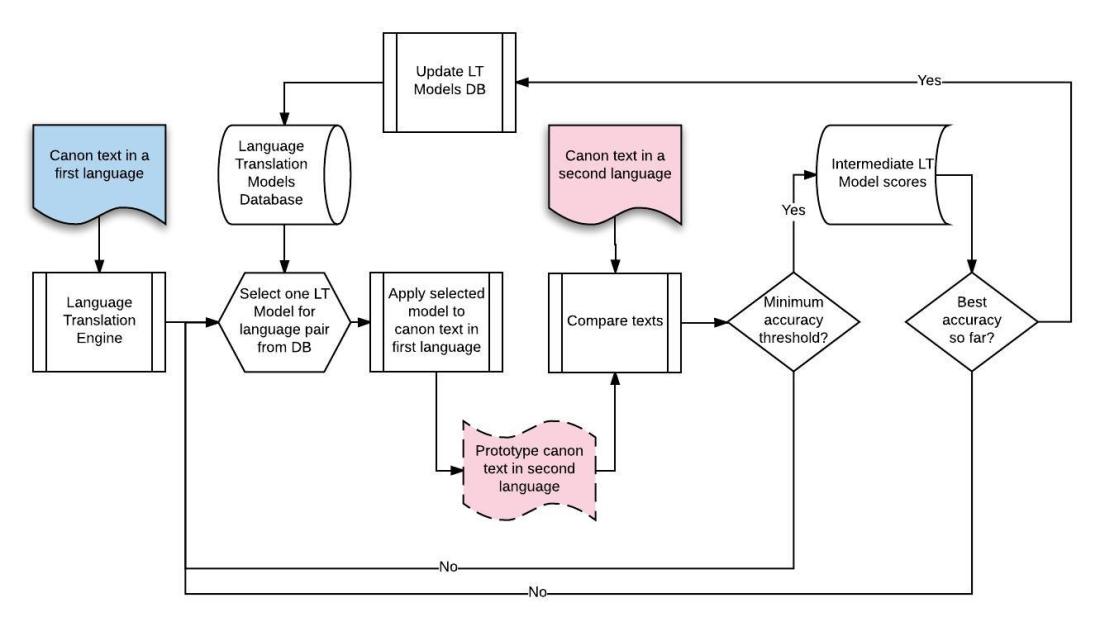
Fig 1: Selection of best model for a given language pair
Given a language pair (source/target) and a plurality of candidate language translation models
- Apply one initial translation model to translate canon text in source language to generate candidate canon text target in the target language.
- Perform word-based comparison of resultant candidate text against the canon text in the target language to generate a compatibility or faithfulness score. This score indicates the efficacy of the selected language model in translating from source to target as a scalar. Resulting translation is compared with canon text in target language following ways:
- If it is the same, maximum score is calculated.
- If it is different, individual words are extracted from the translation and compared with their translations in canon and ranked properly.For example, word black and white are completely different, so for that comparison score will be very low, but not minimal because both words mean a color – it is better than translation of “white” to “carrot”.
Similarly, synonyms are ranked a lot higher, word order etc. Simply said, it is trying to find out how is the meaning of the translated text similar to the canon in target language.
- The result is captured as a tuple of { source, target, model, score } values.
- Select another model from the plurality of candidate models. Repeat steps 1, 2, and 3 until all models are exhausted.
- Select the model with the highest score for given source/target language pair as the model to be employed.

A funny application of the method described herein: https://www.youtube.com/watch?v=4GC83w0z0ec
LikeLike